北京理工大学信息系统及安全对抗实验中心 2022年第19届信息安全与对抗技术竞赛 部分逆向题
Amy’s Code 1 2 3 4 5 6 7 8 9 aim = [149 ,169 ,137 ,134 ,212 ,188 ,177 ,184 ,177 ,197 , 192 , 179 , 153 , 124 , 185 , 129 , 159 , 196 , 142 , 184 ] adv = list ("LWHFUENGDJGEFHYDHIGJ" ) flag = [0 for i in range (20 )] for ind in range (20 ): flag[ind] = aim[ind] - ord (adv[ind]) flag[ind] = flag[ind] ^ ind print ("" .join(map (lambda x: chr (x), flag)))
How_decode xxtea加密,可以用这个findcrypt 工具来分辨常见的加密算法。
本来是比较简单的,可是我自己想尝试使用python实现一遍xxtea算法,因为不太熟悉算法废了些时间,主要是处理一些运算细节。
其实也有现成的C的轮子 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import numpy as npdef int32 (x ): return x & ( (1 <<32 )-1 ) def u2i (x ): x = int32(x) maxint = (1 <<31 ) -1 if x > maxint: x = -maxint - 2 + (x - maxint) return x def i2u (x ): if (x >=0 ): return x maxint = (1 <<31 ) -1 return maxint + (1 <<31 ) + x +1 def xxtea_encode (plain, key, delta ): Len = len (plain) rounds = 52 // Len + 6 for ind in range (len (plain)): plain[ind] = u2i(plain[ind]) rnd_key = 0 while (rounds > 0 ): rnd_key = rnd_key - delta e = rnd_key >> 2 & 3 for ind in range (0 , Len): lst_chr = plain[(ind-1 ) % Len] cipher_ind_nxt = plain[(ind + 1 ) % Len] adv = ( ( ((cipher_ind_nxt<<2 )^(lst_chr>>5 )) + ((cipher_ind_nxt>>3 )^(lst_chr<<4 )) ) ^ ( (cipher_ind_nxt^rnd_key) + (lst_chr ^ key[e ^ ind & 3 ]) ) ) plain[ind] = u2i(plain[ind] + adv) rounds -= 1 return plain def xxtea_decode (cipher, key, delta ): Len = len (cipher) rounds = 52 // Len + 6 for ind in range (len (cipher)): cipher[ind] = u2i(cipher[ind]) rnd_key = 0 rev_rnd_keys = [] for i in range (rounds): rnd_key -= delta rnd_key = int32(rnd_key) rev_rnd_keys.append(rnd_key) while (rounds > 0 ): rnd_key = rev_rnd_keys[rounds-1 ] e = rnd_key >> 2 & 3 lst_chr = cipher[Len - 1 - 1 ] for ind in range (Len - 1 , -1 , -1 ): lst_chr = cipher[(ind-1 ) % Len] cipher_ind_nxt = cipher[(ind + 1 ) % Len] adv = ( ( ((cipher_ind_nxt<<2 )^(lst_chr>>5 )) + ((cipher_ind_nxt>>3 )^(lst_chr<<4 )) ) ^ ( (cipher_ind_nxt^rnd_key) + (lst_chr ^ key[e ^ ind & 3 ]) ) ) cipher[ind] = u2i(cipher[ind] - adv) rounds -= 1 return cipher p = [0x49 , 0x53 , 0x43 , 0x43 , 0x7b , 0x48 , 0x51 , 0x68 , 0x4b , 0x45 , 0x39 , 0x55 , 0x6f , 0x50 , 0x57 , 0x66 , 0x71 , 0x7d ] c = [0xE891B209 ,0x7CE53269 ,0x5DD21C21 ,0x7C10247C ,0x6599594B ,0x32781574 ,0xE603D667 ,0x1D26D9D6 ,0x272CC7E6 ,0x15AEA474 ,0xCA4C71B9 ,0x3379CCA ,0x9A77F1D5 ,0x7B643B55 ,0x7F6A71F8 ,0x3CB1D0C4 ,0x6BFA1C52 ,0xCAD81CB3 ] k = [73 , 83 , 67 , 67 ] d = 0x61C88647 pi = xxtea_decode(c, k, d)
GetTheTable 老实说没有分析出来加密过程,可能是IDA反编译有点儿问题,伪代码的逻辑和base58的算法有点儿区别。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 strr = "ERaQux2mPMMXfoiML7guVUsB3a" alphaTb = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz" enc = [] for i in strr: enc.append(alphaTb.index(i)) print (enc)flag = [] sum = 0 for i in enc: sum = sum *58 + i while (sum > 0 ): res = sum % 256 sum = sum // 256 flag.append(chr (res)) for ind in range (len (flag)-1 , -1 , -1 ): print (flag[ind], end='' )
Sad_Code 数学公式选用z3求解,动态跟一下就能得到大致的逻辑,总之就是做了些简单的char int ascii之间的变换。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from z3 import *int64x8_m1 = Int('int64x8_m1' ) int64x8_0_ = Int('int64x8_0_' ) int64x8_1_ = Int('int64x8_1_' ) int64x8_2_ = Int('int64x8_2_' ) int64x8_3_ = Int('int64x8_3_' ) int64x8_4_ = Int('int64x8_4_' ) int64x8_5_ = Int('int64x8_5_' ) int64x8_6_ = Int('int64x8_6_' ) s = Solver() s.add( int64x8_1_ + 7 * int64x8_0_ - 4 * int64x8_m1 - 2 * int64x8_2_ == 0x1EA758B03 ) s.add( 5 * int64x8_2_ + 3 * int64x8_1_ - int64x8_0_ - 2 * int64x8_m1 == 0x129F7B49D ) s.add( 2 * int64x8_0_ + 8 * int64x8_2_ + 10 * int64x8_m1 - 5 * int64x8_1_ == 0x4CC880F25 ) s.add( 7 * int64x8_m1 + 15 * int64x8_0_ - 3 * int64x8_2_ - 2 * int64x8_1_ == 0x7D7E95653 ) s.add( 15 * int64x8_3_ + 35 * int64x8_6_ - int64x8_4_ - int64x8_5_ == 0xFF2E49303 ) s.add( 38 * int64x8_5_ + int64x8_3_ + int64x8_6_ - 24 * int64x8_4_ == 0x6C07DC086 ) s.add( 38 * int64x8_4_ + 32 * int64x8_3_ - int64x8_5_ - int64x8_6_ == 0x14FD9518AB ) s.add( int64x8_3_ + 41 * int64x8_5_ - int64x8_4_ - 25 * int64x8_6_ == 0x5CC80CE4D ) if (s.check() == sat): print (s.model()) s = [1230193475 , 2067875158 , 1129599313 , 1227706190 , 1447708749 , 1229073737 , 1464097358 , 1413631869 ] for i in s: t=[] while (i>0 ): t.append(chr (i%256 )) i = i // 256 for ind in range (len (t)-1 , -1 , -1 ): print (t[ind], end='' )
mobileA flag分为两部分,一部分去验证AES,密钥、偏移和加密后的值都有,直接用工具解就好,解出来是sadasfsdASDWFSASAFfasf_。
第二部分先算MD5值,然后进行base64加密,接着通过一段算法去重排base64序列来检验,比较简单,逆出来得到md5值,然后找个在线工具解出来是cat。
ISCC{sadasfsdASDWFSASAFfasf_cat}
http://tool.chacuo.net/cryptaes
https://cryptii.com/pipes/base64-to-hex
mobileB 做完之后发现整体的加密逻辑还是比较简单的,但是做的时候就非常烧脑(做题太少,经验不够)。因为在核心的native函数中,反编译得到的代码并不是非常直观。主要的难点是符号很多,而且多次出现多个符号其实对应着同一个变量的情况。再加上涉及到自定义结构体的指针操作,给静态分析带来了较大的麻烦。
面对这样的问题,有两个要点。
首先是不能半途而废,要抽丝剥茧,坚持不懈。(虽然有点儿喊口号之嫌,但确实是经验之谈)
其次是动静结合。如果实在看不出来某个变量的含义,可以动态分析去看它的值,然后猜测它的含义。如果实在看不出来某段代码的作用,比如行数较多的while和for循环体,可以先确定这段代码操作的主要数据对象,然后动态调试看看这段代码对数据对象产生了怎样的影响,进而推测这段代码的作用。
整体逻辑 应用的加密分布在java和native两层中,可以描述成JavaHash(JNIEncode(flag))=Hash。Native层非常直接,经过检查并没有动态注册、init_array之类的操作,stringFromJNI()函数就是静态注册的。flag先被传进native计算,返回的字符串交给java函数计算hash值,然后判断是否与目标值相同。
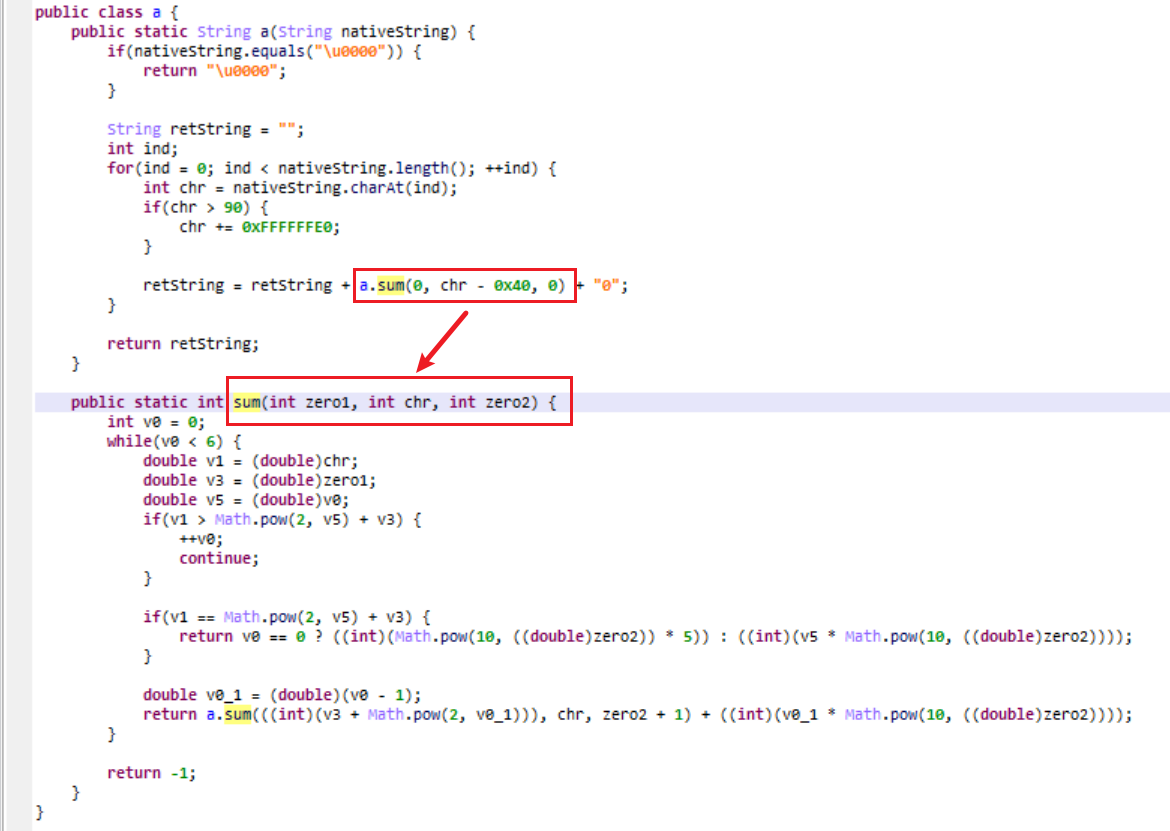
Java层 flag先Java层的加密函数看起来是个hash函数。对于从native返回得到的字符串,把其中的每个字符传进sum()函数计算一个数字,然后把所有数字转成字符串,加上’0’拼接起来,得到类似于"52405201052052301230540405120140305240"这样的hash值。
虽然sum()函数的递归逻辑相对烧脑,但是,如下面的函数截图所示,整个函数的缺陷是它的输入(即sum(0, chr, 0))是有限的,或者说native返回的是个字符串,这也导致这个hash函数的输入是有限的。
因此,遍历sum(0, chr, 0)的所有可能,得到映射表,然后递归求解native返回的字符串的具体值。
简单写个py代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 d = {"51234" :"127" , "1234" :"126" , "5234" :"125" , "234" :"124" , "5134" :"123" , "134" :"122" , "534" :"121" , "34" :"120" , "5124" :"119" , "124" :"118" , "524" :"117" , "24" :"116" , "514" :"115" , "14" :"114" , "54" :"113" , "4" :"112" , "5123" :"111" , "123" :"110" , "523" :"109" , "23" :"108" , "513" :"107" , "13" :"106" , "53" :"105" , "3" :"104" , "512" :"103" , "12" :"102" , "52" :"101" , "2" :"100" , "51" :"99" , "1" :"98" , "5" :"97" } aim = "52405201052052301230540405120140305240" def dfs (pos, path="" ): if (pos >= len (aim)): print ("find: " , path) ret = path.upper() return ret for i in range (pos+1 , len (aim) + 1 ): if (aim[pos:i] in d and aim[i]=='0' ): dfs(i+1 , path + chr (int (d[ aim[pos:i] ])) ) dfs(0 )
Native层 1 在内存空间中排布字符串 一瞬定位到关键函数myjni()。这里出题人应该是修改了basic_string()函数(感觉是,也可能是我不熟知的STL什么的),该函数接收一个字符串,并在目标地址处开辟3个int32。若设字符串长度为Len,则第一个int32为((Len+16)&0xFFFFFFF0)+1,第二个int32存储Len,另外开辟一块空间存放字符串,把地址存放在第三个int32中。
这样一来,预设的12个字符串就对应着3x12个int32。再按照[3, 12, 6, 8, 7, 2, 4, 11, 1, 5, 9, 10]变换顺序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 std::string::basic_string<decltype (nullptr )>((int )&flag1, flag); std::string::basic_string<decltype (nullptr )>((int )struct_3int, "FIXBMTURVPYJGZOQNKASEWCHLD" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[12 ], "UVBXSAFJDGHICZOPQRWELKTMNY" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[24 ], "PZGNVYDEFIJCBKARLUQHMWXOST" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[36 ], "FBSPMACKDRQITWHZLJXYGENOUV" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[48 ], "DTINKLUJCOMEQRAPGSXYFZBHVW" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[60 ], "XAMTFIRBVHEJSCDYZPKLNQGUOW" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[72 ], "EVRYXJACTZGHWOPQSIBUMNDFLK" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[84 ], "VWQGHLZBJEUYFPCSTNIKAXMORD" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[96 ], "FJNVWSTDXYUKMBCZLIGOPEHAQR" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[108 ], "NSKBRTUZEJOPGIFXCDAVWQYLMH" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[120 ], "ASTKPZJDCLYMVHXBNWIUOQGREF" ); std::string::basic_string<decltype (nullptr )>((int )&struct_3int[132 ], "LZWXEHIMFUOPKJGAYTNCBDRSQV" ); temp_add3 = (int *)temp; memset (temp, 0 , sizeof for ( ind1 = 0 ; ind1 != 12 ; ++ind1 ){ crt_ptr = (int *)&struct_3int[12 * adv[ind1] - 12 ]; if ( temp_add3 != crt_ptr ) { crt_str_ptr = (char *)crt_ptr[2 ]; crt_str_realLen = crt_ptr[1 ]; crt_str_fLens = *(unsigned __int8 *)crt_ptr; if ( (crt_str_fLens & 1 ) == 0 ) { crt_str_ptr = (char *)crt_ptr + 1 ; crt_str_realLen = crt_str_fLens >> 1 ; } std::string::assign ((int )temp_add3, (int )crt_str_ptr, crt_str_realLen, (int )crt_ptr + 1 ); } temp_add3 += 3 ; }
2 根据Flag左移字符串并取出aim数组 Flag为12个大写字母,枚举这12个字母,在对应序号的字符串中找到这个字母第一次出现的位置(对应的函数是memchr()),然后循环左移这个字符串,使得这个字母排在第一个,然后又去取出字符串此时下标为9的字母,用于组成aim字符串数组。
这里面的逻辑比较烧脑,原因就是前面提及的频繁出现多个符号对应同一个变量情况,以及指针操作。解决办法就是耐心分析+动静结合。遇到逻辑比较复杂的代码块理起来比较麻烦,就动态调试打上断点,去看这段代码对内存中的变量进行的怎么样的修改,大概就能猜出逻辑。对于v*这样的变量,一时看不出来含义,也可以动态调试去看运行时的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 if ( (flag1 & 1 ) == 0 ) flag_p4_1 = flag1 >> 1 ; if ( flag_p4_1 ) { v12 = !(flag1 & 1 ); indb = 0 ; while ( 1 ) { inda = indb; flag3 = flag2; v17 = v12 << 31 ; if ( v17 ) flag3 = flag_p1; if ( (unsigned __int8)(flag3[inda] - 65 ) > 0x19 u ) break ; if ( v17 ) flag_p4_2 = flag1_1 >> 1 ; if ( flag_p4_2 >= 0xD ) break ; temp_inda3_ptr = &temp[3 * inda]; std::string::basic_string ((int )&tmpStructPtr, (int )temp_inda3_ptr); flag4 = flag2; temp_inda3_ptr1 = *(unsigned __int8 *)temp_inda3_ptr; if ( !(flag1 << 31 ) ) flag4 = flag_p1; flag_i_chr = (unsigned __int8)flag4[inda]; if ( temp_inda3_ptr1 << 31 ) { str_i_realLen = *(_QWORD *)(temp_inda3_ptr + 1 ); str_i_ptr = temp_inda3_ptr[2 ]; str_i_realLen1 = str_i_realLen; } else { str_i_realLen1 = temp_inda3_ptr1 >> 1 ; str_i_ptr = (char *)temp_inda3_ptr + 1 ; } if ( str_i_realLen1 ) { fstOcurPtr = memchr (str_i_ptr, flag_i_chr, str_i_realLen1); if ( fstOcurPtr ) { lostLen = fstOcurPtr - (_BYTE *)str_i_ptr; if ( fstOcurPtr - (_BYTE *)str_i_ptr >= 1 ) { indcInLostLen = 0 ; do { str_i_chr_i_index0 = str_i_ptr2; str_i_realLen2 = HIDWORD (tmpStructPtr); str_i_ptr4 = (char *)str_i_ptr2; str_i_fLen1_And1 = LOBYTE (tmpStructPtr) & 1 ; if ( !str_i_fLen1_And1 ) { str_i_realLen2 = LOBYTE (tmpStructPtr) >> 1 ; str_i_ptr4 = (char *)&tmpStructPtr + 1 ; } str_i_chr_i = *str_i_ptr4; if ( str_i_realLen2 ) { str_i_index1_ptr = (char *)str_i_ptr2 + 1 ; if ( !str_i_fLen1_And1 ) str_i_index1_ptr = (char *)&tmpStructPtr + 2 ; str_i_chr_i_index1 = *str_i_index1_ptr; if ( !str_i_fLen1_And1 ) str_i_chr_i_index0 = (char *)&tmpStructPtr + 1 ; *str_i_chr_i_index0 = str_i_chr_i_index1; str_i_realLen4 = HIDWORD (tmpStructPtr); if ( (LOBYTE (tmpStructPtr) & 1 ) == 0 ) str_i_realLen4 = LOBYTE (tmpStructPtr) >> 1 ; v36 = !(LOBYTE (tmpStructPtr) & 1 ); if ( str_i_realLen4 >= 2 ) { inde = 1 ; do { str_i_ptr1 = (char *)str_i_ptr2; v39 = v36; str_i_next_chr = (char *)str_i_ptr2 + inde + 1 ; if ( v39 ) str_i_next_chr = (char *)&tmpStructPtr + inde + 2 ; temp_chr = *str_i_next_chr; if ( v39 ) str_i_ptr1 = (char *)&tmpStructPtr + 1 ; str_i_ptr1[inde++] = temp_chr; str_i_realLen4 = HIDWORD (tmpStructPtr); if ( (LOBYTE (tmpStructPtr) & 1 ) == 0 ) str_i_realLen4 = LOBYTE (tmpStructPtr) >> 1 ; v36 = !(LOBYTE (tmpStructPtr) & 1 ); } while ( inde < str_i_realLen4 ); } str_i_ptr4 = (char *)str_i_ptr2; if ( v36 ) str_i_ptr4 = (char *)&tmpStructPtr + 1 ; } else { str_i_realLen4 = 0 ; } ++indcInLostLen; str_i_ptr4[str_i_realLen4 - 1 ] = str_i_chr_i; } while ( indcInLostLen != lostLen ); } } } str_i_fLen2 = LOBYTE (tmpStructPtr); str_i_ptr5 = str_i_ptr2; tmpStructPtr = 0.0 ; str_i_ptr2 = 0 ; if ( str_i_fLen2 << 31 ) { *(&aim + inda) = str_i_ptr5[9 ]; operator delete (str_i_ptr5) if ( LOBYTE (tmpStructPtr) << 31 ) operator delete (str_i_ptr2) } else { *(&aim + inda) = BYTE2 (str_i_ptr5); } flag_p4_2 = flag_p4; indb = inda + 1 ; flag1_1 = flag1; v14 = flag_p4; v12 = !(flag1 & 1 ); if ( (flag1 & 1 ) == 0 ) v14 = flag1 >> 1 ; if ( indb >= v14 ) goto LABEL_58; } std::string::basic_string<decltype (nullptr )>((int )c, s); } else { inda = 0 ; LABEL_58: *(&aim + inda + 1 ) = 0 ; std::string::basic_string<decltype (nullptr )>((int )c, &aim); }
3 解密代码 ISCC上面的apk会在一定的时间后被替换,把关键的数据抠出来,可以写个flag脚本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 d = {"51234" :"127" , "1234" :"126" , "5234" :"125" , "234" :"124" , "5134" :"123" , "134" :"122" , "534" :"121" , "34" :"120" , "5124" :"119" , "124" :"118" , "524" :"117" , "24" :"116" , "514" :"115" , "14" :"114" , "54" :"113" , "4" :"112" , "5123" :"111" , "123" :"110" , "523" :"109" , "23" :"108" , "513" :"107" , "13" :"106" , "53" :"105" , "3" :"104" , "512" :"103" , "12" :"102" , "52" :"101" , "2" :"100" , "51" :"99" , "1" :"98" , "5" :"97" } aim = "52405201052052301230540405120140305240" AIM ="" def dfs (pos, path="" ): global AIM if (pos >= len (aim)): print ("find: " , path) AIM = path.upper() for i in range (pos+1 , len (aim) + 1 ): if (aim[pos:i] in d and aim[i]=='0' ): dfs(i+1 , path + chr (int (d[ aim[pos:i] ])) ) def decode (): global AIM aim = AIM adv = [3 , 12 , 6 , 8 , 7 , 2 , 4 , 11 , 1 , 5 , 9 , 10 ] mat = [ "MTURVPYCJGZOQNKASEWFIXBHLD" , "CKTUVBXSAFJDGHIMNYZOPQRWEL" , "WXOPZGNVYDEFIJCBKARLUQHMST" , "FBSNOPMACKDRQITUVWHZLJXYGE" , "OMEJCXYFZBQRAPGSDTINKLUHVW" , "XASQGMTFIRBVHEJUOCDYZPKLNW" , "EHWUVRYOPQSIBXJACTZGMNDFLK" , "VWNIKAXMOGHLZBRDQJEUYFPCST" , "FDXYUKOPJMBCZLIGNVWSTEHAQR" , "NSKBRTUZEJOPGHIFXCDAVWQYLM" , "CLYMVHXASTKNWIUOPZJDBQGREF" , "AYTNCBDRSQLZWXOPKJGEHIMFUV" ] print ("FLAG: " , end='' ) for ind in range (12 ): s = mat[adv[ind] -1 ] indexx = s.index(aim[ind]) align_index = (indexx - 9 + 26 ) % 26 print (s[align_index], end='' ) dfs(0 ) decode()
mobileC 又是一道native逻辑看起来很复杂但是整体算法很简单的题,总的来说多动态调试做得快些。
Java层比较直接,把flag抠出来AES加密一下再转base64得到flagCipher,这个过程的密钥和偏移是固定的。然后把flagCipher和flag本身传到native层的GetStr()函数中,检查返回值是不是”MEH33iZwnESCmAv=ryydXY3=hcRZbjB=7Fd22n3=lFN3DmP=”。
在native层,GetStr函数其实被动态注册替换成了GetStrcT,要去JNI_OnLoad中找对函数才能动态调试。(难怪一开始IDA动态调试老是断不下来)
在GetStrcT中,乍一看逻辑是非常的复杂,而且IDA还原得也不是很好。很多变量前后的符号不一致,静态分析起来很烧脑。此时就需要多用动态调试,关注flagCipher和flag的值传递到了哪些变量中。
总的来说,对于flag,算法先去找”_“符号,然后取”_“之后的6个byte,所以flag是ISCC{xxxxxx_yyyyyyyy}的形式。这6个byte应该对应ascii的0-5,如果不是这个范围会调整为’1’,然后经过vmovl_u16、vmovl_u8这类指令变换为对应的数字0-5,记作key[6]。(因为是动态调试观察结果,所以具体的运算过程没有去关心)
对于flagCipher,它是AES+base64过后的形式,先添加”=”把长度补成6的倍数,然后重新排列。因为Java层的目标值是48位,所以flagCipher补足之后也该是48位。先把flagCipher分割成6byte x 8clip,然后枚举0<=key[i]<6,把8clip中的第key[i]位取出来依次连接在一起。以key=[0,0,1,2,3,4]为例,重排前后的值如下图所示。
现在,反过来从”MEH33iZwnESCmAv=ryydXY3=hcRZbjB=7Fd22n3=lFN3DmP=”逆推。因为这个字符串内部没有重复,所以key是012345的全排列。我们枚举所有的全排列,然后按照算法还原为flagCipher,然后去掉末尾的”====”检查是不是base64的格式,接着用AES去解密,最后看看解出来的flag中”_”之后的6个byte是否和key对得上。事实上,因为AES算法的原因,只需要检查当前还原的flagCipher是否能够成功解密即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 from Crypto.Cipher import AESfrom binascii import b2a_hex, a2b_hexfrom Crypto import Randomimport base64import itertools as itc = "MEH33iZwnESCmAv=ryydXY3=hcRZbjB=7Fd22n3=lFN3DmP=" s = [0 ,1 ,2 ,3 ,4 , 5 ] px = [ i for i in it.permutations(s, 6 )] cipherList = [] def getCipherList (): for p in px: plain = ["=" for i in range (48 )] pp = list (p) ind = 0 for ind1 in range (6 ): for ind2 in range (pp[ind1], 48 , 6 ): plain[ind2] = c[ind] ind += 1 ci = "" .join(plain) if (ci[-5 :] == "=====" ): cipherList.append(ci[0 :-4 ]) return cipherList class PrpCrypt (object def __init__ (self, key ): self.key = key.encode('utf-8' ) self.mode = AES.MODE_CBC self.iv = bytes ("aUBTJjg4Q2NDLg==" , 'utf-8' ) def encrypt (self, text ): text = text.encode('utf-8' ) print (text) cryptor = AES.new(self.key, self.mode,self.iv) length = 16 count = len (text) if count < length: add = (length - count) text = text + ('\0' * add).encode('utf-8' ) elif count > length: add = (length - (count % length)) text = text + ('\0' * add).encode('utf-8' ) print (text) self.ciphertext = cryptor.encrypt(text) return b2a_hex(self.ciphertext) def decrypt (self, text ): cryptor = AES.new(self.key, self.mode, self.iv) plain_text = cryptor.decrypt(a2b_hex(text)) return bytes .decode(plain_text).rstrip('\0' ) if __name__ == '__main__' : pc = PrpCrypt('QERAPG9dPyZfTC5f' ) ciphers = getCipherList() for ci in ciphers: try : e = b2a_hex(base64.b64decode(ci)) d = pc.decrypt(e).encode() print (ci,d) break except : print ("Error" )
EasyCryMobile apk要求Android12L,似乎是难以满足的,所以只能静态分析。isccgetflag54下面的3个activity各自有一些校验逻辑,抠出来逆一下就好。第3个activity用用z3求解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 def check (x, aim ): tmp = x*x if (x*x >= 0xf619 ): tmp = x*x + 0x9e7 return aim == tmp * x % 0xF619 * x % 0xF619 * x % 0xF619 * x % 0xF619 * x % 0xF619 aims = [42349 , 12496 , 33079 , 33079 , 44552 ] for aim in aims: for i in range (256 ): if (check(i, aim)): print (chr (i), end='' ) aims2 = [7101 , 13899 , 18708 , 556 , 1168 ] def check2 (x, aim ): tmp = 1 for i in range (149 ): tmp = tmp * x % 37523 return tmp == aim for aim in aims2: for i in range (256 ): if (check2(i, aim)): print (chr (i), end='' ) def calc (fi ): return (fi * fi - 31921 * (((16819 * fi * fi) >> 16 ) >> 13 )) * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 * fi % 0x7CB1 s = [23598 , 16034 , 20727 , 20727 , 13486 , 2231 , 5750 , 6799 , 21861 , 1528 , 24635 , 6799 , 20754 , 17756 , 27966 , 10529 ] for i in s: for x in range (128 ): if (calc(x) == i): print (chr (x), end='' )